Claude Security left its launch behind with scheduled scans, directory targeting, and CSV or Markdown exports.
Slack and Jira webhooks plus dismissals that stick turn a one-off scan into a weekly review loop.
Six security platforms now build on Opus 4.7, from CrowdStrike and Wiz to Microsoft Security.
It stays Enterprise-only in beta, so here is what a solo studio runs in its place today.
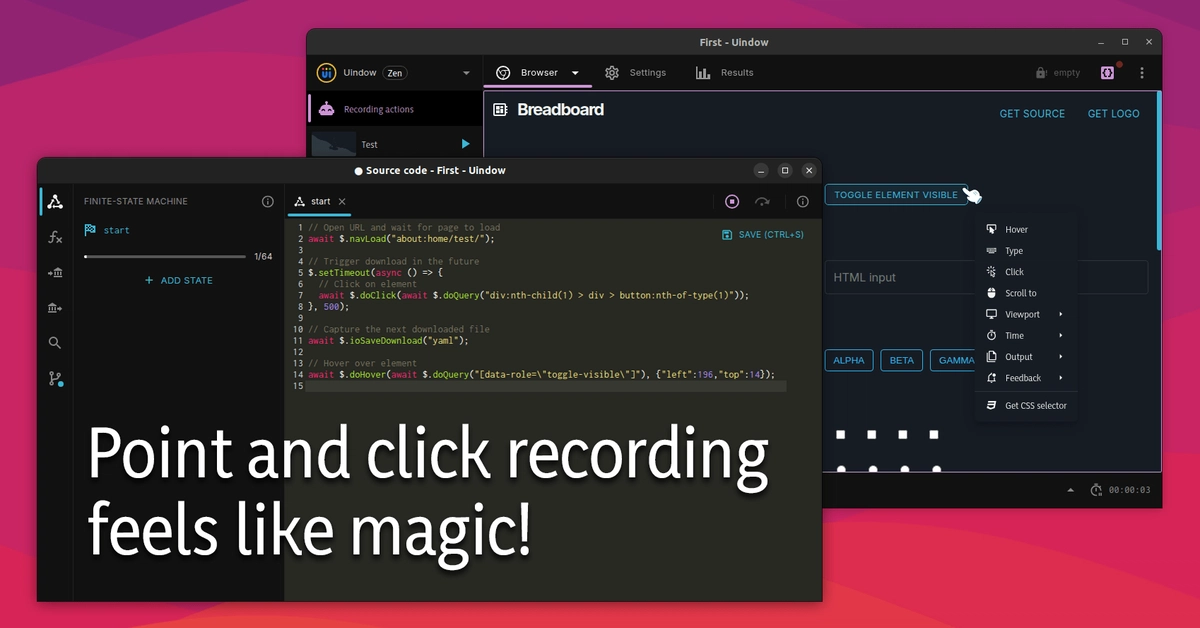
When Claude Security reached public beta about a month ago, it was a sharp scanner wrapped around a thin workflow. You pointed it at a repository, it reasoned through the code the way a security researcher would, and it handed back findings with suggested patches. Useful, but hard to live with day to day. The version sitting in the Claude.ai sidebar this week is a different animal. Scheduled scans, webhooks into Slack and Jira, directory-level targeting, and six security platforms now wiring the same Opus 4.7 model into their own tools.
From Launch to Workflow: What Actually Shipped
At launch the pitch was simple. Scan a repo, explain the vulnerability in plain language instead of a raw CVE dump, propose a fix, and leave the decision to a human. The public-beta launch a month ago covered that first version. The gap was everything around the scan.
This week that gap is mostly filled. You can schedule scans on a cadence instead of running them by hand, which matters because security debt accrues quietly between releases. You can target a single directory inside a large monorepo rather than waiting on the whole tree, so a focused review of the payments module finishes in minutes instead of an hour. You can export findings as CSV or Markdown and drop them straight into an existing tracker or an audit trail. And you can dismiss a finding with a documented reason, with that dismissal persisting across future runs so you are not re-triaging the same false positive every week.
Underneath all of it is a multi-stage validation pipeline. Each finding is checked before it ever reaches you, and every one carries a confidence rating. That validation step is the part that decides whether a scanner is worth keeping, because a tool that cries wolf gets muted within a week. The model reads imports, follows data flow, and reasons about whether a flagged pattern is actually reachable, which is the kind of judgment a regex-based scanner cannot make. You reach the whole thing from the Claude.ai sidebar or at claude.ai/security, with no API integration and no custom agent to build.
In practice the findings cluster around the same few classes: injection through unsanitised input, broken authorization checks, secrets committed by accident, server-side request forgery, and unsafe deserialization. The directory targeting is what makes that tractable on a real codebase. Instead of scanning a 200,000-line monorepo and drowning in a single report, you can scope a run to the service you just changed, review it, and move on. A scoped scan that finishes while you are still in the context of the change is a scan you will actually read.
The Webhook and Dismissal Loop
Two features do the real work of turning a scanner into a habit: webhooks and persistent dismissals.
Webhooks push results into Slack, Jira, or anything that accepts a hook. A scan becomes a ticket without a single copy-paste, and the finding lands where the team already works instead of in a dashboard nobody opens. Persistent dismissals mean a finding you reviewed and rejected stays gone instead of resurfacing on the next pass, which is the single biggest source of fatigue with older tools.
Put them together and you get a loop. Scan on a schedule, surface only the new findings, route them to wherever your team lives, dismiss the noise with a reason, and let the next scan respect that choice. That loop is the entire difference between a tool you run once for a screenshot and one you run every Friday.
It is also where the contrast with the rule-based generation shows. Snyk, Dependabot, and GitGuardian are good at matching known signatures and flagging dependencies with published advisories. They are far less good at explaining why a specific code path in your own logic is exploitable, and they tend to bury the signal under a wall of severity badges. Confidence ratings plus dismissals let you set a noise floor, so only the findings worth a human minute get through. The promise is fewer alerts, each one carrying more context.
Six Platforms Now Run on Opus 4.7
The bigger move is who is building on it. CrowdStrike, Microsoft Security, Palo Alto Networks, SentinelOne, TrendAI, and Wiz are embedding Opus 4.7 into their own security products. On the services side, Accenture, BCG, Deloitte, Infosys, and PwC are deploying Claude-integrated security work for their clients. Anthropic also opened a Cyber Verification Program for organisations doing high-risk cybersecurity work who need access to safeguarded capabilities.
Last week added the governance half. The Compliance API, announced on May 21, exposes Claude Enterprise and Platform activity (prompts, responses, uploaded files, logs, and admin actions) to external security and governance tools. That is the unglamorous piece a security team needs before it will let any model near production code, because without an audit surface the model is a black box the compliance officer cannot sign off on.
The partner news matters even if you never touch the Enterprise product directly. When Wiz or CrowdStrike wires Opus 4.7 into a scanner you already run, the model’s reasoning reaches your pipeline through a tool you have already paid for and trust. That is the quieter distribution story. Not everyone signs up for Claude Security, but a lot of teams will end up running it without ever leaving the dashboard they know.
Read together, this is Anthropic positioning Claude as a layer that security vendors build on, not just a standalone scanner racing the incumbents. It rhymes with Anthropic’s wider cybersecurity bet, where the model is the engine and other companies ship the product on top of it.
What a Solo Studio Can Actually Use Today
Here is the honest part. Claude Security is an Enterprise public beta. Team and Max access is listed as coming soon, and there is no Pro tier in the announcement. As a one-person studio I cannot point it at my repositories yet, and I am not going to pretend otherwise.
So this is what I actually use in its place. Claude Code ships a built-in security review you run with the /security-review command, which makes an on-demand pass over a diff and flags issues before they land. There is also a Claude Code security action for GitHub that reviews pull requests automatically and leaves findings as inline comments on the PR. Both run for individual developers right now, both reason about code the same way the Enterprise product does, and both keep a human approving every patch.
My setup is small. The GitHub action runs on every pull request to main and comments anything it finds, so review happens before merge without me remembering to trigger it. When I am touching auth, payments, or anything that handles a token, I run the review command locally first and read the reasoning, not just the verdict. It catches the boring but dangerous things: a secret about to be committed, an unescaped query, a missing check on a webhook signature. Last month it stopped me from shipping a webhook endpoint that trusted its payload without verifying the signature header, the kind of mistake that reads as fine in review and bites in production. The reasoning, not just the flag, is what made me fix it properly instead of papering over it.
It is worth being clear about what this does not replace. It reasons about your own code, so it complements rather than supplants dependency scanning for known advisories, secret rotation, and the rest of a real security posture. Treat it as a very good reviewer, not a finished program. It is not the scheduled, webhook-routed, dismissal-tracking product either. It is the same instinct at solo scale, and the habits carry straight over if Team access lands the way it is promised.
Bottom Line
Claude Security went from a demo to a workflow in about a month. The scanner was never the hard part. Scheduled runs, dismissals that stick, and webhooks that file the ticket are what make a security tool something you keep instead of something you screenshot once. The model underneath is now shared by six security platforms and a governance API, which says more about the strategy than any single feature does.
For now it sits behind the Enterprise tier, so solo builders get the same engine through Claude Code review instead. Wire the GitHub action into your pull requests, run the review command before you touch anything sensitive, and watch the Team and Max rollout. Read the rest of the Claude coverage in the Lab while you wait.